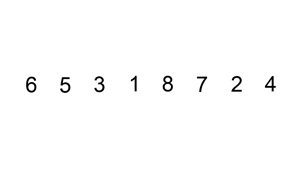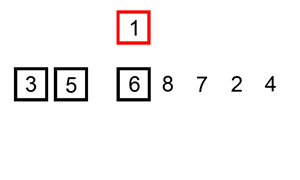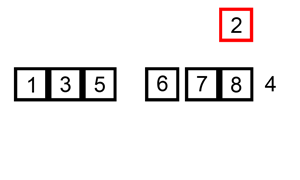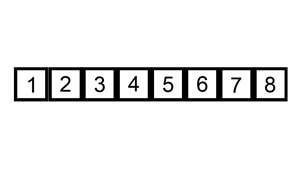
A
Computational problem: Sorting
Input: A sequence of values , ..., .
Output: A permutation (reordering) of the input such that ... .
An
To sort the permutation {8, 3, 6, 7} is an instance of the general sorting problem and {3, 6, 7, 8} is the desired output.
An
A
Objective: This chapter introduces the analysis of algorithms and algorithm design techniques like the incremental method (using insertion sort) and design-and-conquer (using merge sort).
A
It consists of three parts:
Insertion sort is a sorting algorithm that builds the final sorted array one item at a time. At each iteration, insertion sort removes one element from the input data, finds the location it belongs within the sorted list, and inserts it there. It repeats until no input elements remain.
fn insertion_sort(mut input: Vec<i32>) -> Vec<i32> {
for i in 1..input.len() {
let current = input[i];
let mut j = i;
while j > 0 && input[j - 1] > current {
input[j] = input[j - 1];
j -= 1;
}
input[j] = current;
}
input
}
Correctness of the insertion sort algorithm can be proven using loop invariants:
Invariant: At the start of each iteration, the sub-array
input[0:i-1]contains the same elements as the original sub-arrayinput[0:i-1], but in sorted order.
Proof:
input[0..i-1] (an empty subarray) is trivially sorted.input[i - 1], input[i - 2], input[i - 3], ..., input[0] that are greater than input[i] one position to the right. This makes space for input[i] to be inserted in the correct position.
The i variable is incremented and the sub-array input[0..i-1] is still sorted.i = n. At this point, the sub-array input[0..n-1] is sorted and the algorithm has finished.[31, 41, 59, 26, 41, 58] (i = 1, current = 41, j = 1)
[31, 41, 59, 26, 41, 58] (i = 2, current = 59, j = 2)
[31, 41, 59, 26, 41, 58] (i = 3, current = 26, j = 3)
[31, 41, 59, 59, 41, 58] (i = 3, current = 26, j = 2)
[31, 41, 41, 59, 41, 58] (i = 3, current = 26, j = 1)
[31, 31, 41, 59, 41, 58] (i = 3, current = 26, j = 0)
[26, 31, 41, 59, 41, 58] (i = 3, current = 26, j = 0)
[26, 31, 41, 59, 41, 58] (i = 4, current = 41, j = 4)
[26, 31, 41, 59, 59, 58] (i = 4, current = 41, j = 3)
[26, 31, 41, 41, 59, 58] (i = 4, current = 41, j = 2)
[26, 31, 41, 41, 59, 58] (i = 5, current = 58, j = 5)
[26, 31, 41, 41, 59, 59] (i = 5, current = 58, j = 4)
[26, 31, 41, 41, 58, 59] (i = 5, current = 58, j = 4)
Loop invariant: At the start of each iteration, the sum variable holds the sum of the first i-1 elements of the array.
Proof:
i = 0. The sum of all elements in input[0..(i-1)] is trivially zero because that sub-array contains no elements.input[i] to the sum. The i variable is incremented and the sum is still the sum of all elements in input[0..(i-1)].i = n. sum is the sum of all elements in input[0..(i-1)] which equals input[0..(n-1)], which is all the elements in input.fn insertion_sort_desc(mut input: Vec<i32>) -> Vec<i32> {
for i in 1..input.len() {
let current = input[i];
let mut j = i;
while j > 0 && input[j - 1] < current {
input[j] = input[j - 1];
j -= 1;
}
input[j] = current;
}
input
}
fn linear_search(input: Vec<i32>, needle: i32) -> Option<usize> {
let mut result = Option::None;
for i in 0..input.len() {
let number = input[i];
if number == needle {
result = Option::Some(i);
break;
}
}
result
}
Loop invariant: At the start of each iteration, the result variable holds any element in input[0..(i-1)] that equals needle (or empty if none matches).
Proof:
i = 0. There are no elements in input[0..(i-1)], hence, result is empty.result equal to input[i] if input[i] equals needle. The i variable is incremented and the result variable holds any element in input[0..(i-1)] that equals needlei = n or when a match is found. In either, case the result variable holds any element in input[0..(i-1)] that equals needle (or empty if none matches).fn add_binary_integers(a: Vec<u8>, b: Vec<u8>) -> Vec<u8> {
if (a.len() != b.len()) {
panic!("Both a and b must have the same length")
}
let mut result = vec![0; a.len() + 1];
let mut overflow: u8 = 0;
for i in (0..a.len()).rev() {
let bit_sum = a[i] + b[i] + overflow;
result[i+1] = bit_sum % 2;
overflow = if bit_sum >= 2 { 1 } else { 0 }
}
result[0] = overflow;
result
}
To analyze algorithms, we need a model of the machine that it runs on, including the resources of that machine and a way to express their costs.
A common model is the
While simple, the RAM-model analyses are usually excellent predictors of performance on actual machines.
One way to analyze an algorithm is to run it on a particular computer given a specific input.
However, the result of this type of analysis depends on variables that are not
A better form of analysis inspects features that are inherent to the algorithm and its input:
fn insertion_sort(mut input: Vec<i32>) -> Vec<i32> {
for i in 1..input.len() { // Line 1
let current = input[i]; // Line 2
let mut j = i; // Line 3
while j > 0 && input[j - 1] > current { // Line 4
input[j] = input[j - 1]; // Line 5
j -= 1; // Line 6
}
input[j] = current; // Line 7
}
input // Line 8
}
For each i = 1, 2, ..., n, let denote the number of times the while loop test in line 4 is executed for that value of i.
Empty lines are ignored as we assume they take no time.
| Line # | Cost | Times executed |
|---|---|---|
| Line 1 | (this is not n-1 times, because the loop condition is evaluated one more time before terminating). | |
| Line 2 | ||
| Line 3 | ||
| Line 4 | ||
| Line 5 | (subtracting because the loop body executes one less than its condition; remember, represent the number of times the while loop condition is evaluated) | |
| Line 6 | (^^^) | |
| Line 7 | ||
| Line 8 |
For
The
best-case runtime is a linear function of because it can be expressed as , where and are the various constants of running the instructions on the various lines.
For insertion sort, input[0..(i-1)].
Hence, in this case for all .
The worst-case runtime is then given by:
The sum of the first integers is:
This formula comes from adding the sequence forwards and backwards, aligning terms from opposite ends:
There are terms, so:
The cost for the 4th line in the worst-case is . Here, , so:
The
wost-case is a quadratic function of because it can be expressed as , where , and are the various constants of running the instructions on the various lines.
The
In the analysis of algorithms, it's the rate of growth or order of growth that matters. Therefore, only the leading term of the formula is considered, since the lower-order terms and constants are insignificant for large values of . The leading term's constant coefficient is also ignored, since constant factors are less significant than the rate of growth.
To highlight the order of growth of the running time, the theta notation is used.
is .
fn selection_sort(mut input: Vec<i32>) -> Vec<i32> {
for i in 0..(input.len()-1) {
let mut smallest = input[i];
let mut smallest_index = i;
for j in i..input.len() {
if input[j] < smallest {
smallest = input[j];
smallest_index = j;
}
}
input[smallest_index] = input[i];
input[i] = smallest;
}
input
}
Loop invariant: At the start of each iteration of the outer loop, the sub-array input[0..i] contains the smallest i elements of the original array, in sorted order.
Initialization: Before the first iteration, i = 0. The sub-array input[0..i] is empty and trivially sorted.
Maintenance: The body of the outer loop works by finding the smallest element in input[i..n] and swapping it with input[i]. The i variable is incremented and the sub-array input[0..i] is still sorted.
Termination: The loop terminates when i = n-1. At this point, the sub-array input[0..n-1] is sorted and the algorithm has finished.
The loop only needs to run for the first n-2 elements because at n-1, there is only one element left, and by the loop invariant above, it must be the largest element.
Best case time and worst case times are both . Even when the input is sorted (the best case), the inner loop still repeatedly checks every element.
Assuming the element searched for is equally likely to be any element in the array, then on average elements need to be checked when using linear search. In the worst case, the element is either not in the list or at the end, so, elements need to be checked. Using the theta notation, both the worst and average case time for linear search is .
To improve the best-case running time for any sorting algorithm, we can introduce logic that checks if the input is already sorted.
Merge sort algorithm is a sorting algorithm based on the divide-and-conquer technique:
A[p:r] to be sorted into two adjacent sub-arrays, each of half the size.
To do so, compute the midpoint q of [p:r] (taking the average of p and r), and divide A[p:r] into sub-arrays of A[p:q] and A[q + 1: r].A[p:q] and A[q + 1:r] recursively using merge sort.A[p:q] and A[q + 1:r] back into A[p:r], producing the sorted answer.
The base case is reached when the subarray contains one element (which is trivially sorted).
fn merge_sort(input: &mut Vec<i32>, p: usize, r: usize) {
if p >= r {
return;
}
let q = (r + p) / 2;
merge_sort(input, p, q);
merge_sort(input, q + 1, r);
merge(input, p, q, r);
}
fn merge(input: &mut Vec<i32>, p: usize, q: usize, r: usize) {
let left_length = (q - p) + 1; // Explanation for the +1: Given that q >= p, there are two cases: when q == p, there is 1 element; and when q > p, e.g. q = 2 and p = 0, there are 3 elements.
let right_length = (r - q);
let mut left = vec![0;left_length];
let mut right = vec![0;right_length];
for i in 0..left_length {
left[i] = input[p + i]
}
for i in 0..right_length {
right[i] = input[q + i + 1]
}
println!("left: {:?}", left);
println!("right: {:?}", right);
let mut left_index = 0;
let mut right_index = 0;
let mut input_index = p;
while left_index < left_length && right_index < right_length {
if left[left_index] <= right[right_index] {
input[input_index] = left[left_index];
left_index += 1;
} else {
input[input_index] = right[right_index];
right_index += 1;
}
input_index += 1;
}
while left_index < left_length {
input[input_index] = left[left_index];
input_index += 1;
left_index += 1;
}
while right_index <right_length {
input[input_index] = right[right_index];
input_index += 1;
right_index += 1;
}
}
The merge procedure takes time. To demonstrate:
for loops take time.while loops copy exactly one value from left or right back into input,
and each value is copied back into input exactly once. The total time spent in these three loops is .The merge_sort procedure recursively splits the input into halves:
When an algorithm contains a recursive call, the running time can often be described by a recurrence equation or recurrence. A recurrence describes the overall running time on a problem of size in terms of the running time of the same algorithm on smaller inputs.
Let denote the worst-case running time on a problem of size , the recurrence for a divide-and-conquer algorithm can be described using its structure:
This yields the following recurrence:
For merge sort, , .
While in some cases, the array is not divided exactly in half, we can ignore this because at most, the difference is one element.
Also, to simply the equations, the base case is also ignored, because it takes time:
For merge sort, the recurrence can be described as:
merge procedure takes time.Hence, the running time of merge sort on a problem of size can be described as:
The solution to this recurrence is . We can prove this intuitively:
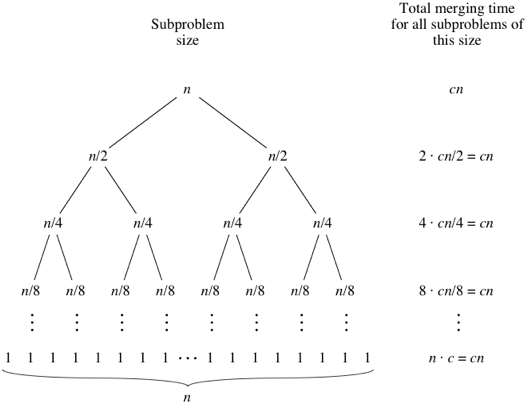
+1 because the root level is level 0.Done with pen and paper.
Assuming the first call to merge_sort(input, p, r), where , then the test if p != r suffices to ensure
that no recursive call has . Argument:
if conditional and stops further division.merge_sort calls:merge_sort(input, p, q). Here, , hence, this will trigger the if conditional.merge_sort(input, p, q). Here, , thus, the important condition that is maintained.merge_sort(input, q + 1, r). Here, , hence, and this will trigger the if conditional.merge_sort(input, q + 1, r). Here, , thus, the important condition that is maintained.Loop invariant: At the start of each iteration i and j points to the smallest element in the left and right arrays, respectively, that is greater than or equal to the last element in input[p..k-1].
Initialization: At the start of the loop, both i and j are set to 0. Since both arrays are sorted, this is trivially the smallest element. Also, , and the elements in input[p..k-1] is zero.
Maintenance: In the loop body, we merge the smallest element between left[i] and right[j] to input[k] and increment i or j (but not both) correspondingly. The k variable is incremented. The loop invariant still holds: input[p..k-1] is still sorted AND left[i] and right[j] are the smallest elements in left and right array that are greater than or equal to the last element of input[p..k-1].
Termination: The loop terminates when all elements of either left or right has been merged.
When the loop terminates, based on the termination condition, either left or right has at least one element that hasn't been merged.
The two while loop handles each case (only one case is possible at a time).
It merges the leftover elements in the remaining array. Since, both arrays are sorted, the remaining array contains only leftover elements
that are greater than any element in the array that was exhausted.
Taken together, the elements in input[p..k-1] represents all the elements in left and right merged together.
TODO
fn insertion_sort_recursive(input: &mut Vec<i32>, r: usize) {
if (r == 0) {
return;
}
insertion_sort_recursive(input, r-1);
insert_into_sorted(input, r)
}
fn insert_into_sorted(input: &mut Vec<i32>, r: usize) {
let mut j = r;
let current = input[r];
while (j > 0 && current < input[j - 1]) {
input[j] = input[j - 1];
j -= 1;
}
input[j] = current;
}
The recurrence relation for the recursive insertion sort is given below: $ T(n) = \begin{cases} \Theta(1) & \text{if } n = 1 \ T(n - 1) + O(n) & \text{if } n > 1 \end{cases} $
The recurrence can be expanded step by step: $ \begin{aligned} T(n) = T(n - 1) + n \ T(n - 1) = T(n - 2) + (n - 1) \ T(n - 2) = T(n - 3) + (n - 2) \end{aligned} $
Adding these terms:
The summation of the first integers is: $ 1 + 2 + 3 + ... + n = \frac{n(n + 1)}{2} $
Thus, the complexity is still: $ T(n) = \theta(n^2) $
fn binary_search(input: Vec<i32>, p: usize, q: usize, needle: i32) -> Option<usize> {
if q == p {
return if input[p] == needle {
Some(p)
} else {
None
}
}
let middle = (p + q) / 2;
if input[middle] == needle {
Some(middle)
} else if input[middle] < needle {
binary_search(input, middle+1, q, needle)
} else {
binary_search(input, p, middle.saturating_sub(1), needle)
}
}
At each step of the recursion, the problem is halved. This continues until either the element is found early, or the input is left with only one element, and that one element either matches or doesn't (this is the worst case). It takes steps to get an element array to a size of through repeated halving. Hence, the worst case running time of binary search is
Using binary search in insertion sort won't improve its runtime. The inner while loop of insertion sort has two responsibilities:
To solve the problem in time, first sort the input with merge sort and then use the procedure below
to determine if any element adds up to x in time:
fn sums_up(sorted_input: Vec<i32>, x: i32) -> bool {
let mut i = 0;
let mut j = sorted_input.len()-1;
while (i != j) {
let sum = sorted_input[i] + sorted_input[j];
if sum == x {
return true
} else if sum > x {
j -= 1;
} else {
i += 1;
}
}
false
}
a. It takes insertion sort time to sort an array on length . If and there are arrays to sort, the total time taken to sort all arrays is .
b. If we apply insertion sort when the elements in merge sort are smaller or equal to , it means we will have leaves, each of size in the recursion tree of merge sort. This means we will have levels, with a total of elements per level. This implies it would take us time to merge all nodes in the recursion tree.
c. The modified merge sort with insertion sort runs in time. Where is the time it takes to perform insertion sort for the bottom nodes. And is the time to merge the top nodes. $k$ must be greater than , else, the running time devolves into the standard merge sort time. But must also be less than , else, the part outgrows the other parts, and the runtime devolves also into the standard merge sort time.
d. must be in the range specified by (c) above. In practice can be picked based on empirical tests that depend on the machine, type of data, etc.
TODO
TODO
a. The five inversions of array [2, 3, 8, 6, 1] are (2, 1), (3, 1), (8, 6), (8, 1), and (6, 1).
b. The array with elements [1, 2, ..., n] that has the most inversions is a reverse sorted array.
There are inversions in such array which can be calculated with the formula below:
$
= \frac{n(n - 1)}{2}
$
c. The notion of inversions is strongly related with the inner while loop of insertion sort. The inner while loop is responsible for swapping out of place elements. Each inversion represents an out-of-place element.
d. The merge sort algorithm can be repurposed to count the number of inversions in an array in time:
fn count_inversions(input: &mut Vec<i32>, p: usize, r: usize) -> usize {
if p >= r {
return 0;
}
let q = (r + p) / 2;
let mut inversions = count_inversions(input, p, q);
inversions += count_inversions(input, q + 1, r);
merge(input, p, q, r, inversions)
}
fn merge(input: &mut Vec<i32>, p: usize, q: usize, r: usize, inversions: usize) -> usize {
let left_length = (q - p) + 1; // Explanation for the +1: Given that q >= p, there are two cases: when q == p, there is 1 element; and when q > p, e.g. q = 2 and p = 0, there are 3 elements.
let right_length = (r - q);
let mut left = vec![0;left_length];
let mut right = vec![0;right_length];
for i in 0..left_length {
left[i] = input[p + i]
}
for i in 0..right_length {
right[i] = input[q + i + 1]
}
let mut left_index = 0;
let mut right_index = 0;
let mut input_index = p;
let mut right_inversion_count = inversions;
while left_index < left_length && right_index < right_length {
if left[left_index] <= right[right_index] {
input[input_index] = left[left_index];
left_index += 1;
} else {
input[input_index] = right[right_index];
right_index += 1;
right_inversion_count += left_length - left_index;
}
input_index += 1;
}
while left_index < left_length {
input[input_index] = left[left_index];
input_index += 1;
left_index += 1;
}
while right_index <right_length {
input[input_index] = right[right_index];
input_index += 1;
right_index += 1;
}
right_inversion_count
}
The
The precision of an exact running time of an algorithm is rarely worth the effort because for large enough inputs, the multiplicative constants and lower-order terms are dominated by the effects of the input size itself.
The
Usually, an algorithm that is asymptotically more efficient is the best choice for all but
The asymptotic notations described below are designed to characterize functions in general. The function can denote the running time, space usage, etc.
All the functions used in the notation must be
The goal of the asymptotic notations is to provide a
The notation specifies an
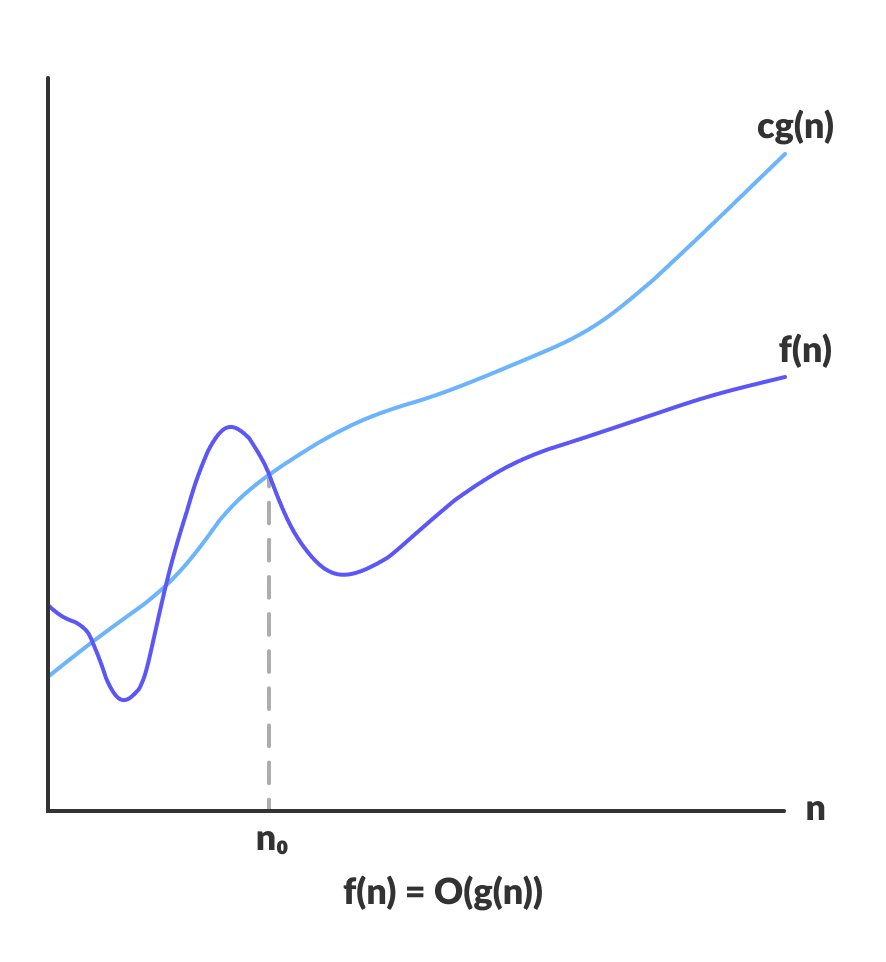
For a given function , we denote by the
A function belongs to the set it there exists positive constants such that for sufficiently large .
The example below uses the formal definition to provide justification for the practice of
The notation provides an
For a given function , we denote by the
The notation specifies
For a given function , we denote by
For all , the function is equal to to within constant factors.
For any two functions, and ,
IFF
and .
The asymptotic notation used to describe an algorithm must be as
The notation is occasionally used in scenarios where the notation will be more appropriate. e.g.